我们平常要提升mysql查询效率的时候,最常见的是给表中加上合适的索引了,那今天小编就来聊聊mysql查询为什么加索引就快?
很多人会觉得索引就等于是一本书的目录,根据目录来找书中的某一页,确实是很快的,要是没有目录,那就需要一页一页去翻书了,大幅降低效率。这个形容也还挺适当的,也是个很经典的索引形容了。
在InnoDB中,每一个索引实际上都是一颗B+树,主键索引称之为聚簇索引,其他非主键索引称作二级索引,每个表中每一行记录值都完整的储存在主键索引的叶子节点上,二级索引的叶子节点保存的是主键的值。
mysql查询为什么加索引就快?mysql索引其实就是一颗B+树。
mysql索引为什么要挑选B+树(下)
换句话说每个表至少都有一个主键索引,并且表中所有的数据行都是存放在主键索引这个B+树的叶子节点上的。假如你给表的其他字段加了索引的话,这个索引便是二级索引了,二级索引也是B+树。
二级索引和主键索引最大的不同在于其叶子节点上保存的值不同,表中全部字段的值都被完整的储存在主键索引的叶子节点上,但二级索引的叶子节点只储存对应主键的值。
咱们举个详细的事例来还原下这一问题。首先出示一个表,表中有3个字段(id,k,m),各自给主键id和字段k建立主键索引和二级索引。
mysql>createtablet(
idintprimarykey,
kintnotnull,
mint(11),
index(k))engine=InnoDB;
然后给表中插进几个数据,用R1、R2、R3、R4、R5表示,插进的实际数据如下所示:R1~R5的(id,k,m)值分别是(100,1,1000)、(200,2,2000)、(300,3,3000)、(500,5,5000)、(600,6,6000)。
刚有说过,主键索引叶子节点上储存完整的整行记录值,二级索引叶子节点储存主键的值,因此上边这个表t的数据在mysql底层的存储就如下示意图。
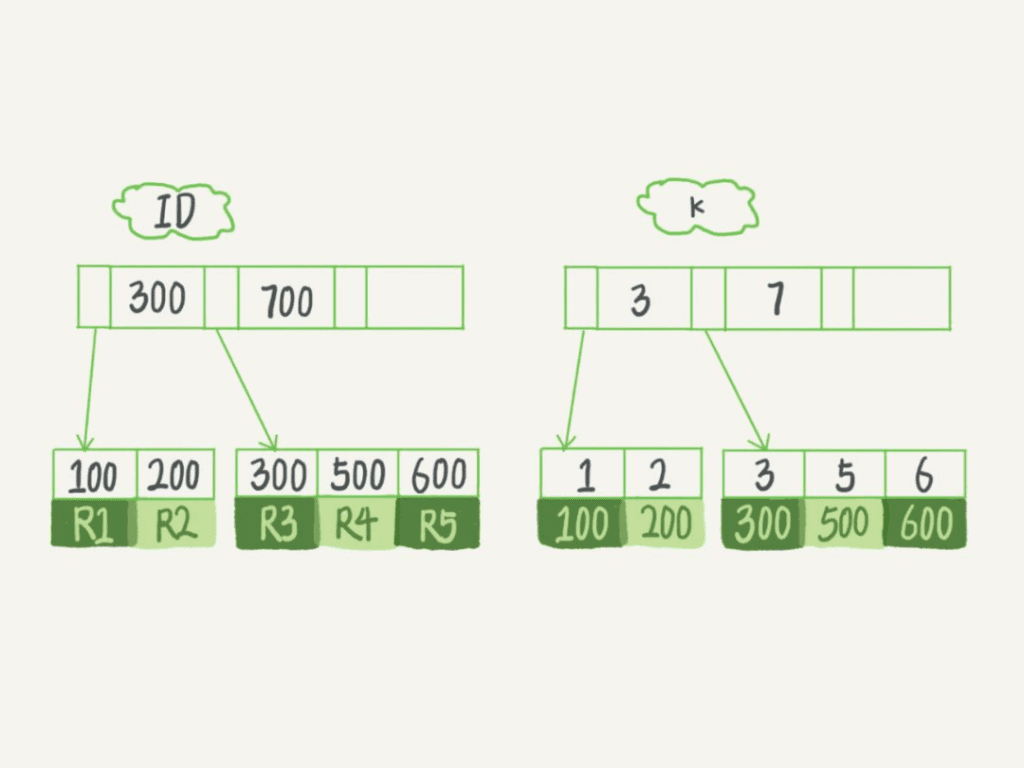
表t一共有3个字段,字段m中没有索引,换句话说表t上有两种索引,因此对应有2个B+树,一个表上有多少个索引,其实就会有多少个B+树。
接下来再来看下有索引和没有索引的查询差别。mysql查询为什么加索引就快?
比如下面这条sql语句,显然没有可用的索引,所以只好走全表扫描了,即把主键索引上的叶子节点从头到尾都扫描一遍,随后每扫描到一行把字段m的值取出来再比对一下,挑选出满足条件的记录,这个查询是非常低效的。
select*fromtwherem>1000andm<3000;
再来看另一条sql语句,这个语句可以用索引k,所以该查询会先去二级索引k这个B+树枝,快速查找符合要求的叶子节点,而这里的叶子节点上只保存了主键的值,因此还要通过获得的主键ID值再回到主键索引上查出全部字段的值,这一过程称作回表。
select*fromtwherek>3andk<6;
这也是mysql查询为什么加索引就快的原因,实际上刚提到的这个回表过程还能再改善的,就是通过覆盖索引,后边的文章我们再来详细说。
有什么问题可以留言交流,原创不容易,希望文章对大家有所帮助。


