
最近有需求,Mysql查询重复数据且保留一条id最小的,本文所有SQL示例以 t_user 用户表为例,里面的 username 列重复代表用户数据重复。
首先,MySQL查重SQL,方便校验数据
SELECT username, count() as num FROM t_user GROUP BY username HAVING count() > 1;查询结果为:
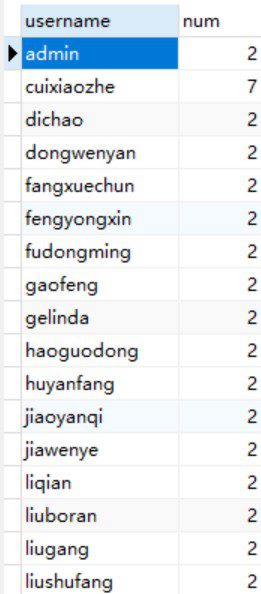
因为我的需求是,针对重复数据,只保留一条id最小的记录。
所以改造下SQL
SELECT min(id) id, username FROM t_user GROUP BY username HAVING count(*) > 1;结果为:
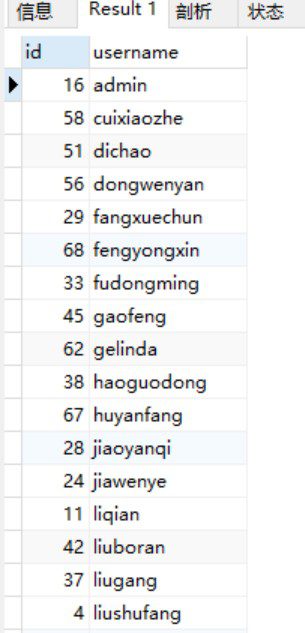
接着,把上面的查询结果当作一张新表,和 t_user 进行关联查询,将id大于上述结果的重复数据中id的数据删除。
这样就达到了删除重复数据中多余的数据,同时保留下来id最小的那条数据。
删除语句sql:
DELETE t_user
FROM
t_user,
( SELECT min( id ) id, username FROM t_user GROUP BY username HAVING count( * ) > 1 ) t2
WHERE
t_user.username = t2.username
AND t_user.id > t2.id此时可以再用第一个查重sql验证下。
Mysql查询重复数据且保留一条效果达到了。
本文由《MySql教程网》原创,转载请注明出处!https://mysql360.com



 苏公网安备32021302001419号
苏公网安备32021302001419号