本文将为大家介绍MySQL的运行原理,我决定先从我MySQL的大脑存储引擎开始,一步一步的细化拆解MySQL内部构成,为大家做更详细的原理性介绍,帮大家将来面试和走向架构岗位做一点点贡献。
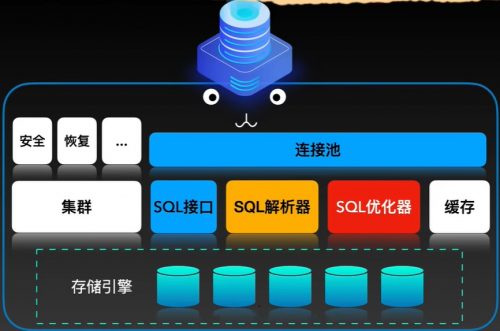
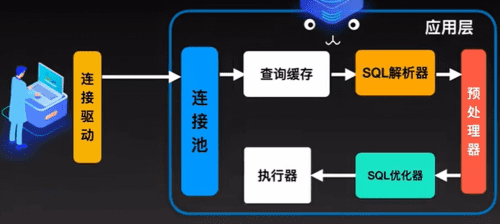
首先inndodb是MySQL的默认存储引擎,它最主要的任务就是接收命令,经过它内部的处理,将结果再返回出来。MySQL通过innoDB提供的数十个handler API发送命令。命令的具体内容就是程序员绞尽脑汁编写的SQL语句转化而来的。SQL语句通过MySQL的连接池传给MySQL,然后再经历了SQL解析、预处理、SQL优化等步骤,最终变成了一组组的执行计划。这一波操作都在MySQL的应用层执行。这些执行计划就是mysql发给innoDB中hander API的命令。
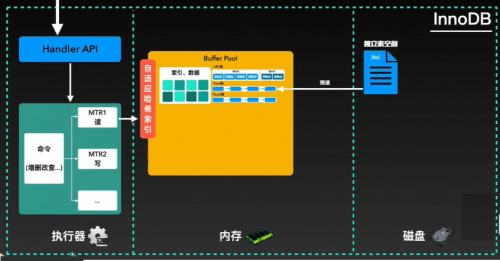
在innoDB收到命令后,首先会在执行器中将各种请求进行微事务拆分,即MTR,mini transaction。对于底层页来说,每一个MTR都是原子访问。如果是一个读指令,则会去内存的buffer中,通过自适应哈希索引进行查找并进行返回。自适应哈希索引集AHI,adaptation hash index, innoDB会根据一些规则为热点页建立自适应哈希索引,提升热点页的查询速度。
如果buffer pool中没有找到所需数据对应的页,则会通过预读的方式从磁盘表空间中加载到buffer pool中,然后返回数据完成读指令。
同时buffer pool会通过free链表、flush链表、LRU链表三个链表来管理这些数据页的写入位置、刷盘位置以及数据页淘汰。当然为了查询找到执行计划中的结果,很可能会执行多个读指令,直到找到最终数据。如果建立了索引,则通常会让这个次数减少。
如果是一个写指令,则要先写入负责事务回滚的undo log,然后把数据记录写入redo LOG buffer,同时根据一定的规则刷到磁盘redo log中。这么做是为了保证在mysql断电时恢复尚未刷到磁盘中的数据。
log写完之后需要将真实数据写入buffer pool。当然,在这之前会根据一定规则判定,是否要写入“变更缓冲”change buffer中。写入change buffer后,将在后续某些时机合并到buffer pool中。
真实数据进入buffer pool之后,接下来就要找机会把内存中的真实数据刷到磁盘中了。为了保证页的完整传输,会先将数据写入double write buffer,同时写入磁盘中系统表空间的double write里。这样即使在页传输到一半时MySQL断电,磁盘上产生了残缺的页也不用担心。
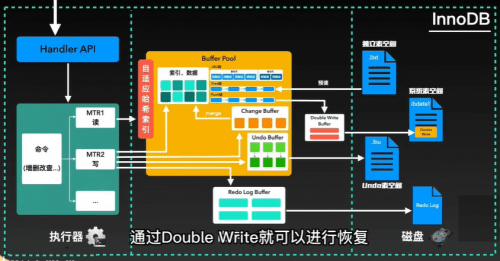
通过double write就可以进行恢复。Double write写完后,最后将真实数据刷到磁盘中就完成了写指令。
MySQL的innoDB除了上述的模块,还有其他一些模块功能,有内存中的锁信息区、数据字典区、additional memory pool, 分别负责锁信息、字典信息、内部共享信息,还有磁盘中的允许用户自定义的通用表空间及存储临时表等数据的临时表空间。
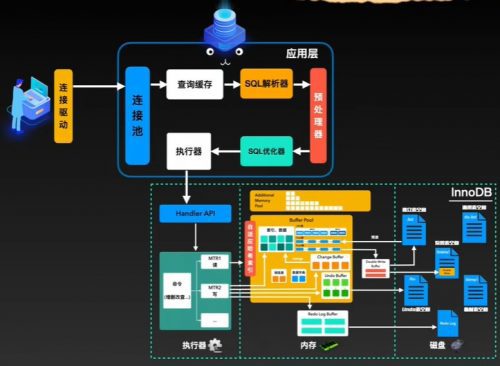
通过这样一整套流程,数据就完成读写了。最终写入或查询的结果都会通过mysql和程序员保持的连接进行返回。
以上就是MySQL内部读写运行原理解析。


 苏公网安备32021302001419号
苏公网安备32021302001419号