
很多做数据分析的小伙伴问我你们做BI的总在讲数据仓库,数据仓库跟其他数据库有啥不同吗?他们的区别到底在哪里?
这个问题其实很多人都问过,简单来说数据仓库的本质就是数据库,存储方式都是一样的,只是两者的定位和服务对象不同,内部的数据组织形式不同,可以从这几个角度来分析一下。
第一,数据服务对象
数据库通常服务于业务,数据仓库通常服务于分析。
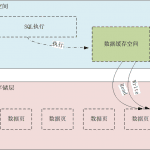
我们通常所提到的数据库一般都是服务于业务系统软件的,不管这个软件是BS架构还是CS架构,例如企业里面常用到的ERP系统、OA系统,或者像我们手机上点餐的APP,网上购票的APP等等,它们特点都是用户在这些软件系统上操作,比如登录填写个人信息,修改个人信息,查询资料等等,数据通过这些软件程序和背后的数据库进行交互,在底层的数据表上进行增删改查的操作,所以通常这些数据库是服务于各种各样跑在操作系统之上的各种业务系统。
数据仓库就不一样,它不是服务于业务信息化系统的,它是服务于分析型应用的,更多的是通过各种BI前端可视化工具或者报表工具来访问数据仓库,最终是面向报表查询数据分析服务。
第二,数据来源
数据库的数据来源于各个业务系统软件程序产生的交互数据,而数据仓库的数据来源则直接是这些业务系统的一个或者多个数据库或者文件,比如sql server、mysql、Excel文本文件等等,也可以简单理解为很多个业务系统的数据库,往数据仓库输送数据,数据仓库是各个数据库的数据的集合体,一个更大的数据库。
数据仓库的建立就是要打通这些基础数据库的数据。
第三,数据状态
数据库在设计的时候很少存放历史数据,通常只是描述某一个业务时刻的数据,随着业务系统用户操作的变化,底层的数据就发生改变,数据仓库本身是不会产生数据,他为了分析的目的会从各个业务系统里面把所有的数据给加载过来,保留历史数据,大部分的数据都是一个静态的状态。
第四,监督方式和数据的冗余
业务系统的数据库为了实现一个业务流程,在表格设计上通常采用三范式建模方式,最小原子列不可细分,主外键不可传递依赖等等,它通过一对多或者多对多的形式减少数据冗余。
而数据仓库在建模方式上既有三范式建模,也有维度建模,有星型、雪花型建模方式。
我们一般通常使用的是Kimball的维度建模,像Kimball的这种维度建模的方式,它是反三范式、反规范性表设计的,保留了大量的数据冗余,主要目的是为了查询的效率,所以业务系统的数据库更多的是增删改查操作,而数据仓库更多的是查询操作,这就决定了建模方式会有很大的差异,一个是面向业务流程,一个是面向分析服务,同时为了底层架构的稳定性和健壮性,数据仓库还会进行底层表的分层设计。
比如我们经常提到的像ODS层、 Staging层、Trans层、Dimension层、Fact层等等,这种分层的好处就是解耦和隔离底层业务系统的变化,对上层模型以及最上面可视化页面的影响,也便于后期的数据维护。
总结
数据仓库的本质仍然是数据库,只是服务对象不同,一个是服务于业务系统,一个是服务于BI可视化分析性应用,服务对象的不同决定了数据库底层的数据组织形式,主要是以三范式建模来适应业务系统频繁增删改查需要,这是业务系统。而数据仓库为了业务分析的目的,因此需要拉通各个业务系统数据库的数据,保留大量历史数据,同时为了分析效率的提升,改变了传统数据库的数据组织形式,最后数据库服务于业务流程,通过业务软件来访问,而数据仓库服务于BI分析,通过BI前端可视化分析工具来访问,这些就是它们的区别和联系。
本文由《MySql教程网》原创,转载请注明出处!https://mysql360.com





 苏公网安备32021302001419号
苏公网安备32021302001419号