
数据库索引的优化及SQL处理过程。学习MySQL数据库你要知道的这些知识点,如果你还想要在IT技术路上走的更好,那就努力学习MySQL技术吧!
想要设计出好的索引,首先必须了解SQL语句在数据库服务器中的处理过程,本文介绍 数据库索引设计与优化 中几个对索引优化非常重要的概念。
谓词
谓词就是条件表达式。 SQL语句的where子句由一个或者多个谓词组成。
WHERESEX=’M’AND(WHIGHT>90ORHEIGHT>190)
上面这个WHERE子句有三个简单谓词:
- SEX = ‘M’
- WRIGHT > 90
- HEIGHT >190
也可以认为是两个组合谓词:
- WEIGHT > 90 OR HEIGHT >190
- SEX = ‘M’ AND (WEIGHT > 90 OR HEIGHT >190)
优化器及访问路径
关系型数据库的一大优势就是,用户无须关系数据的访问方式。其访问路径是由DBMS的一个组件,即 优化器 来确定的。 优化器是SQL处理过程的核心 。
这里以mysql为例展示一个简单的mysql服务器逻辑结构
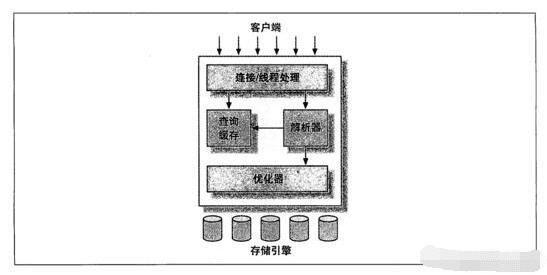
在图中我们可以看到优化器的位置。
在SQL语句能够被真正执行之前,优化器必须首先确定如何访问数据。比如mysql会解析查询并创建解析树,然后对其进行各种优化,包括决定选择合适的索引,决定表的读取顺序。
而 谓词表达式 是索引设计的主要入手点。如果一个索引能够满足SELECT查询语句的所有谓词表达式,那么优化器就很有可能建立起一个高效的访问路径。
索引片及匹配列
如果索引时以B+树的形式组织的,如果有谓词表达式 WHERE A > 100 AND A < 110 ,那么查询到的叶子节点的范围会最终为下图:
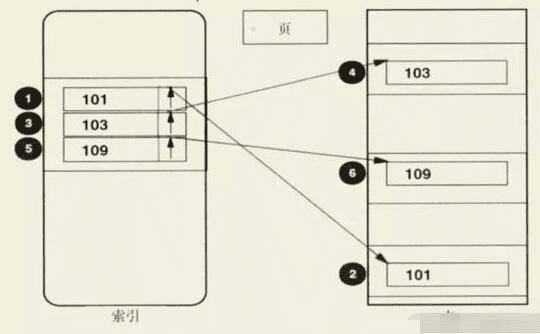
图的左边是索引的一个窄片段,我们称这个片段为 索引片
- 这个片段会被顺序扫描,上面索引行的值在100到110之间,相应的表行将通过同步读从表(也可能在缓冲池)中读取。
- 所以访问路径的成本很大程度上取决于这个索引片的厚度,也就是谓词表达式确定的值域范围。索引片越厚,需要扫描的索引页就越多,需要处理的索引记录也就越多,但最大的开销还是来自于增加的对表的同步读操作,每次表页读取的I/O操作可能需要10ms。相应的,索引片比较窄,就会减少对表的同步读取。
- 索引过滤及过滤列
- 并不是所有的索引列都能够定义索引片的大小。有时候,列可能既存在于WHERE子句中,也存在于索引中,但这个列却不能参与索引片的定义,举个例子。 表上有一联合索引(A,B,C,D),有如下sql语句:
WHEREA=:AANDB>:BANDC=:C
我们需要确定WHERE子句中的谓词是否能够确定索引片大小:
首先我们看在WHERE子句中,该列是否至少有一个 足够简单 的谓词与之对应? 如果有,那么这个列就是匹配列。如果没有,那么这个列及其后面的索引列都是非匹配列。
如果该谓词是一个范围谓词,那么剩余的索引列都是非匹配列。
对于最后一个匹配列之后的索引列,如果拥有一个足够简单的谓词与其对应,那么该列为过滤列。 根据这个方法,我们可以判断出列A出现在一个等值谓词中,这是一个足够简单的谓词,因此A是匹配列,列B是一个范围谓词,也是匹配列。而B后面的列C无法定义索引片(无法让索引片变得更窄),但它依旧可以参与索引片的过滤过程。 也就是说我们通过列A和列B定义了索引片的大小,而列C不能,但是在访问表之前,依旧可以通过列C来过滤记录,能够减少不必要的表访问。列C就属于 过滤列 ,它和列A列B一样重要。
总结:
上述WHERE子句有两个匹配列,列A和列B,他们定义了扫描的索引片。除此之外还有一个列C作为过滤列。所以只有当一行同时满足这三个谓词时才会访问表中的数据。
如果列B的谓词表达式是等值谓词,那么这三个列都可以作为匹配列。
如果取消列A的谓词表达式,那么索引片段就是整个索引的大小,列B和列C都仅仅只能用来过滤。
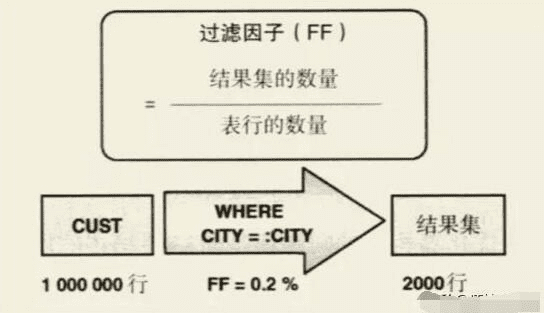
过滤因子
过滤因子描述的谓词的选择性,即表中满足谓词条件的记录行数所占的比例,它主要依赖于列值的分布情况。
计算过滤因子的公式为:
结果集数量/表行的数量
比如我们的一张用户表里有SEX这个字段,当加入一个女性用户,SEX=‘F’的过滤因子就会变大。
如果男性在表中占70%,那么SEX=’M’的过滤因子就是70%,SEX=’F’的过滤因子为30%,SEX列的最差情况下过滤因子为70%,平均过滤因子为50%。
如果男女比例一比一,那么列SEX最差情况下的过滤因子和平均过滤因子都是50%。
我们在评估一个索引是否合适的时候,最差情况下的过滤因子比平均过滤因子更重要,因为最差情况与最差输入相关,即在该输入条件下,基于特定索引的查询将消耗最长的时间。
组合谓词的过滤因子
那我们如何来计算三组合谓词表达式的过滤因子呢?
如果组成谓词的列之间 非相关 ,那么组合谓词的过滤因子可以从单个谓词的过滤因子推导出来。
非相关的意思是两个谓词的值互不影响,例如我们有一张user表,里面有”province”和”city”两个字段,那这就是两个相关的谓词,因为城市的值必须是他所在的省下的城市。而CITY和BD(生日)就是不相关的谓词。
比如组合谓词 CITY = :CITY AND BD = :BD 的过滤因子等于谓词 CITY = :CITY 和谓词 BD = :BD 的过滤因子的乘积。
如果列CITY有2000个不同的值,列BD有2700个不同的值,那么组合谓词的过滤因子就是: 1/2000*1/2700 。那么列组合[CITY,BD]总共有5400000个不同的值。
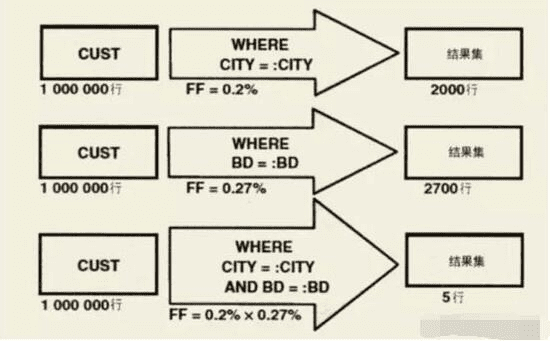
而对于有相关性的列,值会比这小很多。
我们在设计索引结构的时候,需要将SQL语句中的组合谓词看做一个整体来评估过滤因子。
过滤因子对索引设计的影响
很显然,需要扫描的索引片的大小对访问路径的性能影响至关重要。过滤因子越小,筛选出来的索引片的就越小,那就意味着访问表的次数越少。
假设表有联合索引 (MAKE, MODEL, YEAR)
对于sql语句:
SELECTPRICE,COLOR,DEALERNOFROMCARWHEREMAKE=:MAKEANDMODEL=:MODELORDERBYPRICE
MAKE 和 MODEL都是匹配列。如果组合谓词的过滤因子是0.1%,那么所需要访问的索引片大小将为整个索引的0.1%。
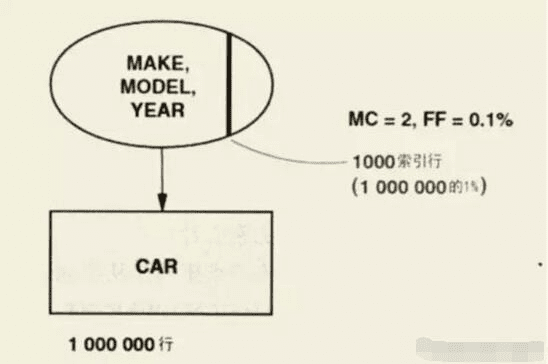
而对于下面这个sql语句,这个索引就不大好了:
SELECTPRICE,COLOR,DEALERNOFROMAUTOWHEREMAKE=:MAKEANDYEAR=:YEAR
由于联合索引的最左匹配原则,匹配列只有MAKE。过滤因子为1%,索引片比较大。
sql语句:
SELECTLNAME,FNAME,CNOFROMCUSTWHERESEX=’M’AND(WEIGHT>90ORHEIGHT>190)ORDERBYLNAME,FNAME
这个SQL语句查找身材高大有一定要求的男性,此时匹配谓词只有一个SEX,过滤因子正常情况下为50%,如果表有100万行记录,那么索引片就有50万行,这就是相当厚的索引片了。
练习
思考一下为以下两个SQL语句设计最佳的索引
SELECTLNAME,FNAME,CNOFROMCUSTWHERESEX=’M’ANDHEIGHT>190ORDERBYLNAME,FNAME



 苏公网安备32021302001419号
苏公网安备32021302001419号