
在 MySQL 中,字符集(Character Set)和排序规则(Collation)密切相关。它们决定了数据库如何存储和比较字符串数据。以下是两者关系的详细解释:
1. 字符集 (Character Set)
字符集决定了字符串存储的编码方式,也就是支持哪些字符以及这些字符如何编码。例如:
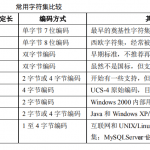
utf8: 支持 Unicode 字符,最多使用 3 字节存储一个字符。latin1: 单字节字符集,支持基本拉丁字符。utf8mb4: 支持完整的 Unicode 字符,包括 Emoji 和其他扩展字符。
2. 排序规则 (Collation)
排序规则定义了在字符集的基础上,字符串的比较和排序方式。排序规则会影响:
- 字符串的大小写是否敏感。
- 字母的排序顺序。
- 特殊字符的处理。
每种字符集可以有多种排序规则。例如:
utf8_general_ci: 对大小写不敏感的通用排序规则。utf8_bin: 二进制排序规则,按字符编码逐字节比较,大小写敏感。utf8_unicode_ci: 基于 Unicode 的标准排序规则,支持更多语言特性。
3. 字符集与排序规则的关系
- 字符集决定可用的排序规则: 每个字符集都对应一组支持的排序规则。例如,
utf8支持utf8_general_ci、utf8_bin等,但不支持latin1_swedish_ci。 - 排序规则与字符集绑定: 每次选择字符集时,必须指定对应的排序规则。如果不指定排序规则,MySQL 会使用该字符集的默认排序规则。
- 示例:对于
utf8,默认排序规则是utf8_general_ci。
- 示例:对于
4. 排序规则的主要差异
- 大小写敏感性 (Case Sensitivity):
_ci(Case Insensitive): 对大小写不敏感。例如,'a' = 'A'。_cs(Case Sensitive): 对大小写敏感。例如,'a' ≠ 'A'。_bin(Binary): 直接比较二进制值,区分大小写且效率最高。
- 语言特性: 不同语言可能有特定的排序规则。例如:
utf8_unicode_ci: 使用 Unicode 标准规则,能更好处理多语言排序。utf8_general_ci: 通用规则,性能较高但支持语言特性较少。
5. 选择字符集和排序规则的影响
- 存储: 字符集影响字符的存储空间。例如,
latin1每字符占 1 字节,而utf8mb4最多占 4 字节。 - 查询性能: 排序规则影响字符串比较的复杂度。
_bin规则通常比_ci规则快,因为不需要考虑大小写转换或语言特性。 - 查询结果: 排序规则影响排序结果。例如,法语中的字母带重音符可能在不同规则下排序不同。
6. 如何选择字符集和排序规则
- 国际化支持:
- 使用
utf8mb4字符集。 - 排序规则选择
utf8mb4_unicode_ci,确保支持多语言特性。
- 使用
- 大小写敏感应用:
- 使用
_cs或_bin排序规则,如utf8mb4_bin。
- 使用
- 仅英文或拉丁字符:
- 使用
latin1字符集和默认排序规则latin1_swedish_ci。
- 使用
- 性能优先:
- 在不需要语言特性的场景下,选择性能更高的
utf8_general_ci。
- 在不需要语言特性的场景下,选择性能更高的
字符集决定了存储的字符种类,排序规则决定了字符串比较和排序的方式。两者必须匹配使用。合理选择字符集和排序规则可以平衡存储需求、多语言支持和性能需求。例如,utf8mb4_unicode_ci 适合多语言环境,utf8_general_ci 性能较高但支持语言特性有限。

 苏公网安备32021302001419号
苏公网安备32021302001419号