
在MySQL中,select查询是最常用也是其中最重要的操作之一。那么在MySQL中执行一条select查询语句时,到底会发生什么呢?本文将深入探究select查询语句在MySQL中的执行细节,带您了解其背后的运行原理和实现过程。
- 数据存储和访问
在探究select查询语句的执行过程之前,我们先来了解一下MySQL中数据的存储和访问方式。
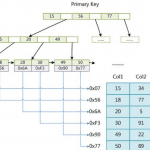
MySQL中的数据存储在表中,每个表由若干个行组成,每个行又由若干个列组成。每个表可以由一个或多个文件组成,其中包括数据文件和索引文件。数据文件中存储着实际数据,而索引文件中存储着用于查询和排序的索引。
当我们执行一个查询时,MySQL需要访问数据文件和/或索引文件来寻找符合条件的数据。数据文件和索引文件的组合就是MySQL存储引擎,MySQL支持多种存储引擎,如InnoDB、MyISAM等。不同的存储引擎有不同的数据存储和访问方式,因此对于同一条查询语句,使用不同的存储引擎可能会有不同的执行效果。
- 语句解析、优化和执行
在MySQL服务器接收到一条查询语句后,它需要先对该语句进行解析、优化和执行。
2.1 语句解析
语句解析是将查询语句分解成可以被MySQL理解的数据结构的过程。MySQL使用自己的语法解析器将查询语句转换成一个解析树,这个解析树由许多节点组成,每个节点都代表着一部分查询语句。这些节点包括SELECT、FROM、WHERE、GROUP BY、HAVING和ORDER BY等。
2.2 语句优化
语句优化是MySQL对查询语句进行的重要处理过程,它最终会生成一种最优的查询执行计划。MySQL会根据查询语句的复杂度、表的大小、索引使用情况、存储引擎类型等因素选择最优的执行计划,以便最快地得到需要的结果。
MySQL的优化器会分析语句的每个部分,并决定实施哪种执行计划。执行计划是MySQL从查询语句所需数据中选出并组成的操作序列。MySQL会使用许多算法来决定执行计划,如排序算法、连接算法等。
2.3 语句执行
语句执行是MySQL将生成的执行计划转换为操作系统可以理解的实际操作的过程。在这个阶段,MySQL会从表中读取数据,并对数据进行过滤、排序、合并等操作,以得到最终的结果。
在执行查询语句时,MySQL会按照以下步骤进行:
- 打开需要访问的表或索引
- 执行WHERE子句中的条件匹配
- 执行JOIN操作(如果有)
- 执行GROUP BY和HAVING操作(如果有)
- 执行SELECT子句中的操作
- 执行ORDER BY操作(如果有)
- 返回结果集并关闭表或索引
3.查询性能优化
在MySQL中执行查询时,我们需要考虑查询的性能问题。在这一部分中,我们将讨论如何对查询进行优化,以提高其性能。
3.1 合理使用索引
索引是MySQL提供的一种高效读取数据的方式,它可以让查询的效率得到显著提升。但是,索引的建立也会带来一定的额外开销,因此我们需要合理使用索引来获得最佳的性能。
合理使用索引需要考虑以下几个方面:
- 对于重复率高的列,不适合建立索引
- 越少的字符越能提高索引效率
- 不使用NULL值的字段,可以将该字段建立为表的主键或唯一索引
- 不要过度索引,太多索引会增加查询语句解析和执行的开销
3.2 确定查询范围
查询范围的确定可以帮助MySQL快速定位需要的数据,从而提高查询效率。
可以通过以下方式来确定查询范围:
- 利用WHERE子句中的条件过滤数据
- 使用LIMIT语句来限制结果集的大小
- 尽可能使用主键或唯一索引,以快速定位行
3.3 避免查询全表
查询全表是一种十分耗资源的操作,应该尽量避免。我们可以通过以下方式来避免查询全表:
- 尽可能使用WHERE子句中的条件来筛选数据
- 尽可能使用索引来优化查询
- 合理建立索引,使得MySQL能够快速定位符合条件的行
4.总结
本文深入探究了MySQL中select查询语句的执行原理和过程,包括数据存储和访问、语句解析、优化和执行,以及查询性能优化等方面。在实际的应用场景中,我们需要根据具体情况来选择合适的存储引擎、合理使用索引、确定查询范围、避免查询全表等方法来提高查询的效率和性能。
通过对MySQL中select查询语句的深入理解和掌握,我们可以更好地应对复杂的数据查询和分析需求,为我们的工作和生活带来更多的便利和价值。



 苏公网安备32021302001419号
苏公网安备32021302001419号