
在实际开发中,可能会遇到数据库多条数据重复了,此时我们需要删除重复数据,只保留一条有效数据,用SQL语句怎么实现呢,下面我们模拟一下:
1.准备重复数据:
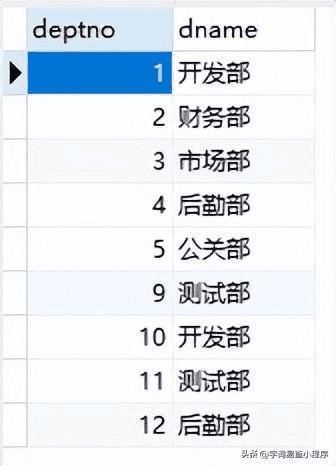
2.过滤出存在重复数据的信息:
SQL语句:
SELECT dname FROM dept GROUP BY dname HAVING count( dname ) >1
数据库筛选结果:

3.从重复数据中筛选出一条需要保存的数据:
SQL语句:
SELECT min( deptno ) -- max( deptno ) FROM dept GROUP BY dname HAVING count( dname ) >1
这里使用数据库的MIN或者MAX函数筛选出一条需要保存数据即可。
数据库筛选结果:
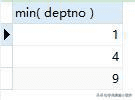
4.删除重复数据,即从重复的数据中,删除掉需要保留数据之外的所有信息:
SQL:
DELETE FROM dept WHERE dname IN ( SELECT dname FROM dept GROUP BY dname HAVING count( dname ) > 1 ) -- 过滤出重复的dname AND deptno NOT IN ( SELECT min( deptno ) AS deptno FROM dept GROUP BY dname HAVING count( dname ) > 1 ) -- 过滤出不在需要保留的id之外的所有id
如果是oracle数据库,上面的SQL语句可以正常执行,可是换成mysql数据库,SQL语句执行会报错:
1093 - You can't specify target table 'dept' for update in FROM clause
含义:不能在同一表中查询的数据作为同一表的更新数据。
适用于mysql数据库的SQL:
DELETE FROM dept WHERE dname IN ( SELECT * FROM ( SELECT dname FROM dept GROUP BY dname HAVING count( dname ) > 1 ) a ) AND deptno NOT IN ( SELECT * FROM ( SELECT min( deptno ) AS deptno FROM dept GROUP BY dname HAVING count( dname ) > 1 ) b )
数据库最后数据:

到这里,删除重复数据成功!https://mysql360.com
文中如果有什么错误,欢迎指出。



 苏公网安备32021302001419号
苏公网安备32021302001419号